A class is a user-defined type provided to represent a concept in the code of a program. Essentially, all language facilities beyond the fundamental types, operators, and statements exist to help define better class or to use them more conveniently.
Sometimes I have problems defining the concept that is going to be
encapsulated as a class. Other times, the naming is hard, and I result
to common patterns like FooManager.
A class is the language mechanism for separating the interface to a type (to be used by all), and its implementation (which has access to otherwise inaccessible data).
Concrete Types
The basic idea of concrete classes is that they behave “just like built-in types”. The defining characteristic of a concrete type is that its representation is part of its definition. If the representation changes in any significant way, a user must recompile.
For some concrete types, e.g. std::vector and std::string, the
representation may have pointers to data stored in the free store
(dynamic memory, heap). Such types can be considered resource handles
with carefully crafted interfaces.
The “representation is part of definition” property allows us to:
- Place objects of concrete types on the stack and in other objects.
- Refer to objects directly (and not just through pointers or references).
- Initialize objects immediately and completely.
- Copy and move objects.
An Arithmetic Type
// From Stroustrup2018
class complex {
double re, im; // representation: two doubles
public:
complex(double r, double i) :re(r), im(i) {}
complex(double r) :re(r), im{0} {}
complex() :re{0}, im{0} {}
double real() const { return re; }
void real(double d) { re = d; }
double imag() const { return im; }
void imag(double d) { im = d; }
complex& operator+=(complex z) {
re += z.re;
im += z.im;
return *this;
}
complex& operator-=(complex z) {
re -= z.re;
im -= z.im;
return *this;
}
complex& operator*=(complex); // defined out-of-class somewhere
complex& operator/=(complex); // defined out-of-class somewhere
};
notes that complex’s representation
has to be compatible with what Fortran provided 60 years ago.
Why is C++’s compatibility with Fortran important? Intel says something similar . It seems that mixing Fortran and C++ is commonplace, e.g. IBM’s instructions .
Inlining
Simple operations (such as constructors, +=, imag, etc.) must be
inlined (implemented without function calls in the generated machine
code) . paints a more subtle picture of the effect of inlining on
performance. Inline functions might make the executable:
- Larger as the inlined functions get expanded in multiple places.
- Smaller if the expansion generates less code than the code to push/pop registers/parameters.
- Faster by removing unnecessary instructions, increasing cache hits because of improved locality.
- Slower if it’s larger and therefore more thrashing.
Inlining might even be irrelevant to speed because most systems are not CPU-bound (most are I/O-bound, database-bound, or network-bound).
Compilers are not obligated to inline (or not to inline). The
meaning of inline has evolved to be “multiple definitions are
permitted” rather than “inlining is preferred”.
Default Constructors
By defining a default constructor (one that can be invoked without
arguments), one eliminates the possibility of uninitialized variables of
that type. One can also have complex() = delete;, which will cause a compiler error if the default constructor
gets selected.
Out-of-Class Operator Definitions
Operations that do not require direct access to the representation can be defined separately from the class definition, e.g.
complex operator+(complex a, complex b) { return a += b; }
complex operator-(complex a, complex b) { return a -= b; }
complex operator-(complex a) { return {-a.real(), -a.imag()}; }
complex operator*(complex a, complex b) { return a *= b; }
complex operator/(complex a, complex b) { return a /= b; }
An argument passed by value is copied, and therefore it can be modified
without affecting the caller’s copy. Had
we received the arguments by reference, implementing a + b as a += b
because of performance may lead to buggy programs because users expect
a + b to make a copy.
The return a += b; statement caught me off-guard. Looks like invalid
syntax.
ISOCPP has considered letting users define their own operators several times, and the answer has always been that the likely problems outweigh the likely benefits .
Other languages, like Haskell, allow custom operators. I’ve sometimes
found the syntax unintuitive, e.g. <|>.
Some operators, e.g. ., ::, sizeof, and ?:, cannot be
overridden. Furthermore, one can’t define an operator all of whose
operands/parameters are of primitive types.
Defining Instance Variables
Bar | optional<Bar> | unique_ptr<Bar> | |
|---|---|---|---|
| Supports delayed construction | ✅ | ✅ | |
| Always safe to access | ✅ | ||
Can transfer ownership of Bar | ✅ | ||
Can store subclasses of Bar | ✅ | ||
| Movable | If Bar is movable | If Bar is movable | ✅ |
| Copyable | If Bar is copyable | If Bar is copyable | |
| Friendly to CPU caches | ✅ | ✅ | |
| No heap allocation | ✅ | ✅ | |
| Memory usage | sizeof(Bar) | sizeof(Bar) + sizeof(bool) (+ padding) | sizeof(Bar*) (+ non-empty custom deleter if present) when null; sizeof(Bar*) + sizeof(Bar) otherwise |
| Object lifetime | Same as enclosing scope | Restricted to enclosing scope | Unrestricted |
Call f(Bar*) | f(&bar_) | f(opt_.value()) or f(&*opt_) | f(ptr_.get()) or f(&*ptr_) |
| Remove value | N/A | opt_.reset() or opt_ = nullopt | ptr_.reset() or ptr_ = nullptr |
Containers
A container is an object holding a collection of elements. It should be simple to understand, establish useful invariants, and provide range-checked access.
Motivation for the Destructor Mechanism
Although C++ provides an interface for plugging in a garbage collector, aim to use the destructor pattern to reduce headache (e.g. GC’s availability not being guaranteed) :
class Vector {
public:
Vector(int s) : elem{new double[s]}, sz{s} { // Ctor: acquires
// resources from the free store.
for (int i = 0; i != s; ++i) // Initialize elements
elem[i] = 0;
}
~Vector() { // Destructor: release resources
delete[] elem;
}
double& operator[](int i);
int size() const;
private:
double* elem; // Points to an array of sz doubles
int sz;
};
The technique of acquiring resources in a constructor and releasing them
in a destructor, known as Resource Acquisition Is Initialization
(RAII), allows us to avoid naked new and delete operations in
general code.
In RAII, resource acquisition must succeed for initialization to succeed. The resource is guaranteed to be held between when initialization finishes and finalization starts (holding the resources) is a class invariant, and to be held only when the object is alive. If there are no object leaks, then there are no resource leaks.
RAII only works for resources acquired and released by stack-allocated objects, where there is a well-defined static object lifetime. Heap based objects must be deleted along all possible execution paths to trigger their destructor.
Notice that regardless of the number of elements, the Vector object
itself is always the same size. A fixed-size handle referring to a
variable amount of data “elsewhere” is a common technique for handling
varying amounts of information in C++.
In C++, stack unwinding (popping one or more frames off the stack to
resume execution elsewhere in the program) is only guaranteed to happen
if the exception is caught somewhere. If it’s not caught, terminate is
called and stack unwinding at this point is implementation-defined. The
OS usually releases program resources at termination, so it usually
works out.
Initializing Containers
class Vector {
public:
Vector(std::initializer_list<double>);
// ...
void push_back(double); // Useful for an arbitrary number of elements.
// ...
};
The std::initializer_list is a standard-library type know to the
compiler. Whenever we use a {}-list, the compiler creates an object of
type initializer_list to give to the program, e.g. Vector v = {1, 2, 3, 4, 5}. The initializer-list constructor may be defined as:
Vector::Vector(std::initializer_list<double> lst)
: elem{new double[lst.size()]}, sz{static_cast<int>(lst.size())} {
copy(lst.begin(), lst.end(), elem) // Copy from lst into elem
}
An object of type std::initializer_list<T> is a lightweight proxy
object that provides access to an array of objects of type const T.
Copying a std::initializer_list does not copy the underlying objects.
The static_cast is used to convert from the unsigned size_t returned
by initializer_list::size(). We’re assuming that a handwritten list
won’t have more elements than the largest integer. *casts should be
used sparingly as they are error-prone.
Containers may define their container::size_type as they wish. It may
not always be std::size_t. That said, std::size_t can store the
maximum size of a theoretically object of any type (including array). A
type whose size cannot be represented by std::size_t is ill-formed.
Programs using other types, e.g. unsigned int, for array-indexing and
loop counting may fail on 64-bit systems when the index exceeds
UINT_MAX or if the program relies on 32-bit modular arithmetic.
Abstract Types
An abstract type is a type that completely insulates a user from implementation details. The interface is decoupled from the representation, and there are no genuine local variables.
// Container is an abstract class because it has a pure virtual
// function.
class Container {
public:
// It is common for abstract classes to not have a constructor. After
// all, there is no data to initialize.
// The destructor is declared virtual so that derived classes can
// define implementations. Someone destroying a Container through a
// pointer has no idea what resources are owned by its implementation.
virtual ~Container() {}
// The "= 0" syntax says the function is pure virtual. Some class
// derived from Container MUST define the function.
virtual double& operator[](int) = 0;
virtual int size() const = 0;
};
An abstract class cannot be instantiated; we can’t do Container c; -
we don’t even know the size of Container.
Using an Abstract Class
For Container to be useful, we need a class that implements the
functions required by the interface:
// ": public" can be read as "is derived from".
// Vector_container is said to be derived from class Container, or a
// subclass.
// Container is said to be a base class of Vector_container, or a
// superclass.
// The derived class is said to inherit members from its base class, and
// so the use of base and derived classes is commonly referred to as
// inheritance.
class Vector_container : public Container {
public:
Vector_container(int s) : v(s) {}
// `-Winconsistent-missing-destructor-override` warns about the
// missing "override" below.
// <span class="citation-ref"><a href="#clangDiagnosticsMissingOverrides"></a></span>
~Vector_container() {}
// The use of "override" is optional, but being explicit helps the
// compiler catch mistakes.
//
// `-Winconsistent-missing-override`, which warns if the "override"
// keyword is not specified when it should, is enabled by default.
// <span class="citation-ref"><a href="#clangDiagnosticsMissingOverrides"></a></span>
double& operator[](int i) override { return v[i]; }
int size() const override { return v.size(); }
private:
Vector v;
};
Vector_container can be initialized and referred to as a Container,
i.e. Container* p = new Vector_container(10).
A Container can be used like this:
void use(Container& c) {
const int sz = c.size();
for (int i = 0; i != sz; ++i)
std::cout << c[i] << '\n';
}
use(Container&) has no idea if its argument is a Vector_container,
or some other kind of container, and it doesn’t need to know.
If the implementation of Vector_container changed, use(Container&)
need not be re-compiled. The flip side of this flexibility is that
Container objects must be manipulated through pointers or references.
Objects are constructed “bottom up” (base first) by constructors, and destroyed “top down” (derived first) by destructors.
The Virtual Function Table
A Container object must contain information to allow it to select the
right function to call at runtime. A common implementation is a virtual
function table, or simply the vtbl. Each class with virtual functions
has its own vtbl.
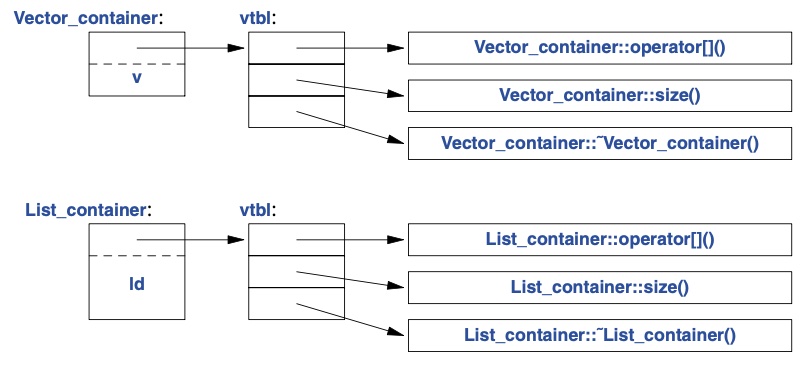
Graphical representation of a virtual function table. Source: Stroustrup2018-Ch4.
The implementation of the caller needs only to know the location of the
pointer to the vtbl in a Container, and the index used for each
virtual function. The virtual call mechanism can be made almost as
efficient as the “normal function call mechanism (within 25%).
Protected and Private Inheritance
There is also protected inheritance, and private inheritance. It is all about access to the inherited members. From :
class A {
public:
int x;
protected:
int y;
private:
int z;
};
class B : public A {
// x is public; y is protected; z is not accessible from B.
};
class C : protected A {
// x is protected; y is protected; z is not accessible from C.
};
class D : private A { // 'private' is default for classes.
// x is private; y is private; z is not accessible from D
};
Notice that derived classes cannot expose inherited members beyond the access level defined in the base class. But a derived class can hide the inherited members.
Note that neither C nor D can be accessed through a pointer or
reference to A, i.e. A* a = new C(); fails to compile with the error
'A' is an inaccessible base of 'C'.
class D : private A {}; can be read as, "D is implemented in terms
of A (with a possibly more restricted interface)”.
Class Hierarchies
A class hierarchy is a set of classes ordered in a lattice created by
derivation (e.g., : public).
class Shape {
public:
virtual ~Shape() {}
virtual Point center() const = 0;
virtual void move(Point to) = 0;
virtual void draw() const = 0;
virtual void rotate(int angle) = 0;
};
class Circle : public Shape {
public:
Circle(Point center, int radius);
Point center() const override { return center_; }
void move(Point to) override { center_ = to; }
void draw() const override;
void rotate(iny) override {}
private:
Point center_;
int radius_;
};
class Smiley : public Circle {
public:
Smiley(Point center, int radius)
: Circle{center, radius}, mouth_{nullptr} {}
void move(Point to) override;
void draw() const override;
void rotate(int) override;
void add_eye(std::unique_ptr<Shape> s) {
eyes.push_back(s);
}
void set_mouth(std::unique_ptr<Shape> s);
virtual void wink(int eye_index);
private:
// We use unique_ptr so that we don't have to manually call delete in
// our destructor. unique_ptr will call delete on our behalf.
std::vector<std::unique_ptr<Shape>> eyes_;
std::unique_ptr<Shape> mouth_;
};
Circle is a kind of a Shape, but the “is a kind of a” relationship
starts breaking down when relating Smiley to Circle. Perhaps a
better definition would be class Smiley : private Circle {}; because
while Smiley is implemented using a Circle, it is awkward to say
that it’s a circle.
A class hierarchy offers interface inheritance: an object of a
derived class can be used used wherever an object of a base class is
required. A stronger version of this is
The Liskov Substitution Principle: If \(S\) is a subtype of \(
T\), then objects of type \(T\) in a program may be replaced with
objects of type \(S\) without altering any of the desirable properties
of that program (e.g. correctness).
A class hierarchy also offers implementation inheritance, e.g.
Smiley uses Circle’s constructor, and may use Circle::draw(). Such
base classes often have data members and constructors.
There’s an alternate school of though popularized by Item #33 in Scott Myers’ “Effective C++”: Make non-leaf classes abstract. The major argument, as gleaned from this mailing list , is to avoid partial assignment.
dynamic_cast<Derived*>(p) returns nullptr if p does not point to a
Derived, while dynamic_cast<Derived>(*p) throws a bad_cast
exception if *p is not of type Derived. For example:
void use(Shape* shape) {
if (Smiley* smiley = dynamic_cast<Smiley*>(shape)) {
// `shape` points to a Smiley.
}
}
The Case for Private Virtual Functions
Consider this traditional base class:
class Widget {
public:
virtual int Process(Gadget&);
virtual bool IsDone();
};
Each virtual function is specifying two things: the interface
(because it’s public), and the implementation detail (because derived
classes can replace the implementation).
To separate interface from internals, consider the Template Method pattern:
class Widget {
public:
int Process(Gadget&); // Uses DoProcess...()
bool IsDone(); // Uses DoIsDone()
private:
virtual int DoProcessPhase1(Gadget&);
virtual int DoProcessPhase2(Gadget&);
virtual bool DoIsDone() = 0;
};
With this separation, there are several benefits:
- The base class has complete control of its interface and policy. It can enforce invariants, and insert instrumentation in the non-virtual interface functions.
- The interface and the implementation can be changed independently,
e.g. adding
DoProcessPhase3would only affect classes that subclassWidget, while users ofWidgetwill be unaffected.
If the derived class need to invoke the base implementation of a virtual
function, then declare the virtual function in the protected section.
Otherwise, default to virtual functions being private because they
exist to customize behavior, and not to be called.
My intuition was that a private virtual function could not be overridden in a derived class because the derived class can’t access the virtual function. But there’s a difference, the derived class indeed can’t call the base class’s virtual function, but it can override it!
References
- A Tour of C++ (Second Edition). Chapter 2. User-Defined Types. Bjarne Stroustrup. 2018. ISBN: 978-0-13-499783-4 .
- A Tour of C++ (Second Edition). Chapter 4. Classes. Bjarne Stroustrup. 2018. ISBN: 978-0-13-499783-4 .
- inline specifier. en.cppreference.com . Accessed May 12, 2022.
- Default constructors. en.cppreference.com . Accessed May 12, 2022.
- Operator Overloading, C++ FAQ. isocpp.org . Accessed May 13, 2022.
- Inline Functions, C++ FAQ. isocpp.org . Accessed May 13, 2022.
- Thrashing (computer science). en.wikipedia.org . Accessed May 13, 2022.
- Resource acquisition is initialization - Wikipedia. en.wikipedia.org . Accessed May 28, 2022.
- std::initializer_list - cppreference.com. en.cppreference.com . Accessed May 28, 2022.
- std::size_t - cppreference.com. en.cppreference.com . Accessed May 28, 2022.
- Diagnostic flags in Clang — Clang 15.0.0 git documentation > Winconsistent-missing-*override. clang.llvm.org . clang.llvm.org . Accessed May 28, 2022.
- What is the difference between public, private, and protected inheritance in C++? - Stack Overflow. stackoverflow.com . Accessed May 28, 2022.
- Virtuality. Herb Sutter. www.gotw.ca . Sep 1, 2001. Accessed May 28, 2022.
- c++ - Inheritance: 'A' is an inaccessible base of 'B' - Stack Overflow. stackoverflow.com . Accessed May 28, 2022.
- Why does C++ allow private members to be modified using this approach? - Stack Overflow. stackoverflow.com . Accessed May 28, 2022.
- Damian Conway quote: C++ tries to guard against Murphy, not Machiavelli. Damian Conway. www.azquotes.com . Accessed May 28, 2022.
- Liskov substitution principle - Wikipedia. Barbara Liskov. en.wikipedia.org . Accessed May 28, 2022.
- Type erasure - Wikipedia. en.wikipedia.org . Accessed May 30, 2022.
- 05-type-classes. Brent Yorgey. www.seas.upenn.edu . Accessed May 30, 2022.
- abseil / Tip of the Week #123: absl::optional and std::unique_ptr. abseil.io . Accessed May 31, 2022.
quotes Doug McIlroy:
What is the context of this quote?