This page contains remarks on Haskell that I encountered when working with source files that span multiple AoC 2021 problems.
and have Haskell solutions. It’ll be nice to compare how they solved the problems. I don’t want to end up perfecting the wrong approach!
Setting Up Haskell Env for AoC
To manage dependencies, Cabal and Stack are pretty popular. Stack incorporates the Cabal build system.
The package structure is of the form:
2021
├── advent-of-code-y2021.cabal
├── app
│ └── Main.hs
├── src
│ ├── AoC2021.hs
│ ├── SonarSweep.hs
│ └── SonarSweep.md
└── test
└── AoC2021Test.hs
I ended up using Cabal only as I thought it wouldn’t have too many bells
and whistles. cabal init --interactive got most of my .cabal file
set up.
cabal run advent-of-code-y2021 runs my solutions to the AoC problems .
cabal run advent-of-code-y2021-test runs some checks based on the
sample inputs on AoC problem description .
has a more comprehensive setup, e.g. specifying
which problem to run, running tests, and running benchmarks. They even
published
an advent-of-code-api
package
that
abstracts away the network calls!
VS Code Setup
Haskell , Haskell Syntax Highlighting , and haskell-linter (which is a wrapper for ndmitchell/hlint ) are pretty useful.
hlint is especially useful as some of the resources linked in
https://www.haskell.org/documentation/
use idioms that have since been improved.
VS Code’s Haskell Language Server is currently a bit buggy in that the symbols may not update leading to erroneous flagging of code that compiles fine. Restarting the language server every once in a while is a tad inconvenient.
Sometimes VS Code reports that it can’t find both GHC and HLint.
’s suggestion of launching VS Code via
code . works.
Debugging Haskell
A lot of the errors are caught by the compiler given the strong typing.
One option is to load the .hs file into GHCi and experiment in there.
$ ghci
GHCi, version 8.10.7: https://www.haskell.org/ghc/ :? for help
Loaded package environment from /Users/dchege711/.ghc/x86_64-darwin-8.10.7/environments/default
Prelude> :load src/Dive/Dive.hs
[1 of 1] Compiling Dive.Dive ( src/Dive/Dive.hs, interpreted )
Ok, one module loaded.
*Dive.Dive>
Haskell GHCi Debug Adapter Phoityne seems like the de-factor debugger for VS Code. I’m having issues of the form:
test/AoC2021Test.hs:5:1: error:
Could not load module ‘Paths_advent_of_code_y2021’
it is a hidden module in the package ‘advent-of-code-y2021-0.1.0.0’
Use -v (or `:set -v` in ghci) to see a list of the files searched for.
|
5 | import Paths_advent_of_code_y2021 (getDataFileName)
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
… so I need to figure out how to send arguments from the extension to GHCi. That said, GHCi comes with a debugger included so that’s promising!
Literate Programming
Literate Haskell intrigued me , but I don’t use it much because it’s not well-integrated into VS Code’s intellisense and linting extensions.
In terms of writing code, Literate Haskell works as expected on Emacs. However, the literate portion is LaTeX, and having a multi-language code doesn’t work well with HighlightJS (the plugin API does not support line-by-line decision making). I’m more interested in reading code that is well formatted, so I’ll forego Literate Haskell, as HighlightJS is a tighter requirement for me.
uses , which allows one to put code inside markdown code blocks. Entangled then extracts code and writes it to traditional source files, and syncs changes made in either the markdown or the source file.
Entangled is written in Haskell, and mostly by Hidding! Small world. The project is still in active development, so something to keep an eye on.
It’s a pretty nifty concept, and superior to my current approach of using a Hugo shortcode to embed the source file into the generated HTML file. My current approach doesn’t display both the source and the markdown in the same space when I’m editing the content.
uses to generate markup from source code. Haddock reminds me of Python’s Sphinx , Java’s Javadoc and JavaScript’s JSDoc .
Cabal has integrations with Haddock, and that’s useful for generating
docs for the package. For some reason, cabal init doesn’t generate a
Setup.hs that is needed in runhaskell Setup.hs haddock --internal.
Update: cabal haddock and cabal v2-haddock are alternative ways of
using haddock on a package.
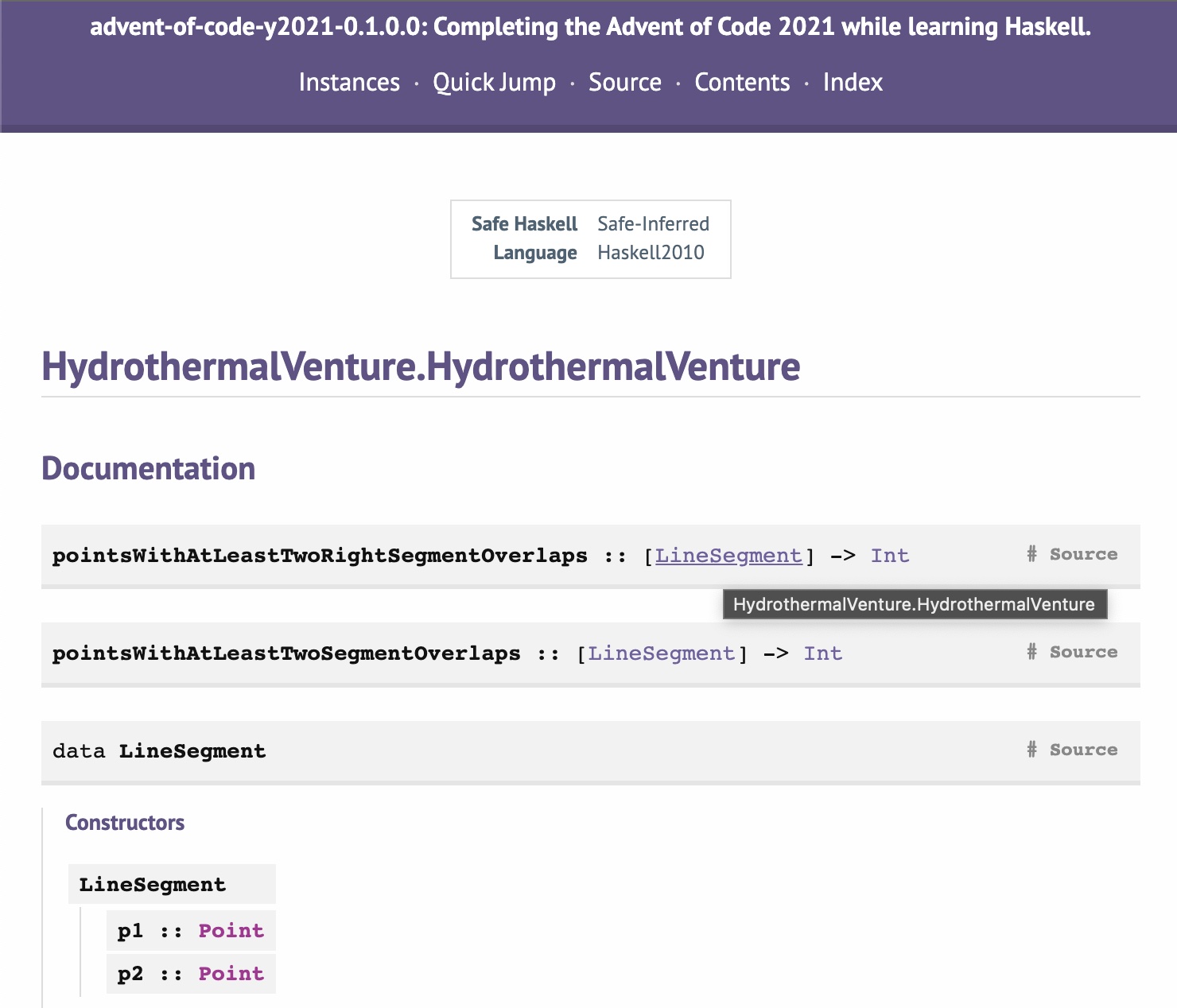
“cabal haddock” generates documentation similar to ones at Hackage. Notice the “# Source” link.
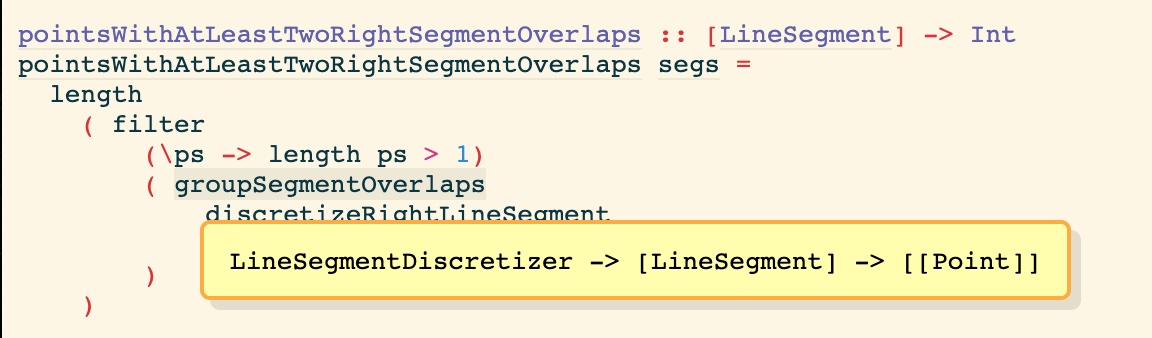
Clicking on the “#Source” link takes me to this browsable version of the code
However, I’d like the code inlined, and the non-code portions of the
.lhs files rendered as normal text instead of being included inside a
code block, like how is structured.
Maybe the lhs2TeX package can get me there?
Aha, lhs2tex --markdown -o Foo.md Foo.lhs gets me a nice .md file that
could use some additional processing, e.g. removing the two leading
lines that only have %s, adding YAML, changing the opening back-ticks
to have hs (HighlightJS guesses the language correctly though). Maybe
lhs2TeX has some customization options that won’t require me to whip
up a Python script? Didn’t find anything promising. This script
suffices:
#!/bin/zsh
if [[ $1 == "--all" ]]
then
working_dir="$(dirname $0)"
lhs_files=($working_dir/**/*.lhs)
elif [[ $1 ]]
then
lhs_files=($1)
else
printf "Either supply a filepath to an .lhs file, or use '--all'\n"
exit 1
fi
for lhs_file in $lhs_files ; do
output_file=${lhs_file/.lhs/.md} # Replace .lhs with .md
# Delete the first 2 lines which only have a `%` character.
# The 2nd expression replaces `\#` with `#`. The former is needed for .lhs
# to compile. As an SO user said, when in doubt, add another backslash.
lhs2tex --markdown $lhs_file | sed -e '1,2d' -e s.^\\\\\#.\#. > $output_file
printf "Published $output_file\n"
done
VS Code lacks multi-mode, which is helpful when editing .lhs files.
Emacs it is! The editor shows highlights the non-code portions as
Haskell, but the language server doesn’t trip up. I’ll keep using VS
Code for now, especially with the
Run On Save
extension
for regenerating the markdown as I save.
The Standard Library
uses the RIO library to replace the
standard Prelude. aims to be the de-facto
standard library for Haskell development, as the base package is quite
minimal, has some contentious APIs, and avoid re-inventing the wheel in
the name of fewer dependencies.
More on dependency management .
RIO lives in
https://github.com/commercialhaskell
alongside Stack, and
Stackage. I’m not especially keen on using RIO for AoC 2021. But it’s
good to know that it exists, and why it exists.
Partial functions (e.g. head, tail, init, last, and (!!)) in
the Prelude (the module with a bunch of standard definitions that get
implicitly imported into every Haskell program) are an example of a
contentious standard library API. A partial function is one that
could crash for some inputs (e.g. head [] crashes because an empty
list doesn’t have a first item). A total function is one that is
well-defined on all possible inputs.
Lazy Evaluation
Read [1808.08329] When You Should Use Lists in Haskell (Mostly, You Should Not) . I am using lists a lot, and whenever I fret about efficiency, I mumble something to do with lazy evaluation in Haskell.
Pattern matching drives evaluation. Expressions are only evaluated when pattern-matched, and only as far as necessary for the match to proceed, and no farther. For example, given these definitions:
repeat :: a -> [a]
repeat x = x : repeat x
take :: Int -> [a] -> [a]
take n _ | n <= 0 = []
take _ [] = []
take n (x:xs) = x : take (n-1) xs
… we expect take 3 (repeat 7) to evaluate to [7, 7, 7]. A
step-by-step evaluation looks like:
take 3 (repeat 7)
-- Matches clause 2, which needs the 2nd arg. Expand `repeat 7` one
-- step.
= take 3 (7 : repeat 7)
-- Matches clause 3. (3-1) not yet evaluated as not needed for
-- pattern-matching.
= 7 : take (3-1) (repeat 7)
-- (3-1) <= 0 forces evaluation of (3-1).
= 7 : take 2 (repeat 7)
-- Matches clause 2; expand 2nd arg one step.
= 7 : take 2 (7 : repeat 7)
= 7 : 7 : take (2-1) (repeat 7)
= 7 : 7 : take 1 (repeat 7)
= 7 : 7 : take 1 (7 : repeat 7)
= 7 : 7 : 7 : take (1-1) (repeat 7)
= 7 : 7 : 7 : take 0 (repeat 7)
= 7 : 7 : 7 : []
The GHC compiler uses graph reduction, where the expression being evaluated is represented as a graph, so that different parts of the expression can share pointers to the same subexpression. Haskell’s runtime works out the memoization aspect of dynamic programming on our behalf!
Parsing Input
For the first two AoC problems, my parsing technique has basically been:
solutionX :: IO ()
solutionX = do
fileName <- getDataFileName "dayX/input.txt"
withFile
fileName
ReadMone
( \h -> do s <- hGetContents h
print (solveX lines (fromString s))
)
Granted, IO is lazy, but there are improvements to the above sort of parsing.
For example, Day 1 has input of the form:
199
200
import RIO
import qualified RIO.Text as Text
readInput :: MonadIO m => m [Int]
readInput = do
text <- Text.lines <$> readFileUtf8 "data/day01.txt"
return $ mapMaybe (readMaybe . Text.unpack) text
Notice how readInput parses the input and takes care of converting
into expected data types [Int] and takes care of parsing uncertainty
with *Maybe. In comparison, my
SonarSweep.num*Increases
and
Dive.productOfFinalPosition*
functions receive a [String] which they then parse into intended
types.
Day 2 had input of the form:
forward 5
down 5
forward 8
… and I parsed it using regular expressions. used the Parsing module, which results in pretty concise code:
data Instruction = GoForward Int | GoUp Int | GoDown Int deriving (Show)
instructions :: Parser [Instruction]
instructions = sepEndBy1 (lexeme direction <*> integer) eol
where direction = (string "forward" $> GoForward)
<|> (string "up" $> GoUp)
<|> (string "down" $> GoDown)
readInput :: (Monad IO m, MonadReader env m, HasLogFunc env) => m [Instruction]
readInput = readInputParsing "data/day02.txt" instructions
These parsing utilities are not in the packages on Stackage. Turns out
has a custom
app/Parsing.hs
,
that extends functionality from , which is
an advanced fork of
Text.Parsec
, the
“default” parsing library for Haskell.
My takeaway is to first get the hang of Text.Parsec, as it probably
has more “official” resources, e.g.
Real World Haskell > 16. Using
Parsec
.
Monad
uses a MonadIO and that code looks
cleaner.
My initial perspective on monads is one of trepidation. I’ve encountered a lot of: Actually, [prior definition] does not encompass a monad™, but the more we discuss examples, the more you’ll grok monads™.
(◎ ◎)ゞ
Monads derive from category theory, but I lack the mathematical maturity to make sense of the terminologies. Hoping to get a Haskell programmer’s understanding of monads instead.
Values of type IO a are descriptions of effectful computations,
which, if executed would (possibly) perform some effectful I/O
operations and (eventually) produce a value of type a. Values of type
IO a are only ever executed by the Haskell runtime system, and they’re
are passed to the runtime system via the special function main :: IO (). Given the special main function, there exists a need for ways to
combine smaller IO computations, and pass them off to main. The
(>>=) and (>>) operators (described below) come in handy for this.
Instances of Monad (e.g. IO monad) satisfy left identity, right
identity, and associativity. The minimal complete definition is the
(>>=) (bind) operator. From a Haskell programmer’s perspective, a
monad is an abstract datatype of actions. Haskell’s do expressions are
syntactic sugar for writing monadic expressions.
A binary operation (one that acts on two elements to produce one element) is said to be associative if rearranging the parentheses in an expression doesn’t change the result. For instance, addition of real numbers is an associative operation, e.g. \((2 + 3) + 4 = 2 + (3 + 4) = 9\), while subtraction of real numbers is not, e.g. \( (2 - 3) - 4 \ne 2 - (3 - 4) \). Note that associativity is different from commutativity (does the order of two operands affect the result?).
Let \((S, *)\) be a set \(S\) equipped with a binary operation \(*\). Then an element \(e\) of \(S\) is called a left identity if \(e * a = a\) for all \(a\) in \(S\), and a right identity if \(a * e = a\) for all \(a\) in \(S\). If \(e\) is both a left identity and a right identity, then it is called a two-sided entity, or simply an identity. For example, where \(S\) is the set of real numbers, and \(*\) is the addition operator, \(0\) is the identity element.
uses the phrase “instances of Monad”, which
requires a bit of digging from my side.
Type classes correspond to sets of types which have certain operations defined for them. For instance,
class Eq a where
(==) :: a -> a -> Bool
(/=) :: a -> a -> Bool
… can be read as: Eq is declared to be a type class with a single
parameter, a. Any type a that wants to be an instance of Eq must
define two functions, (==) and (/=), with the indicated type
signatures.
Type class polymorphic functions work only for types which are instances
of the type class(es) in question. For example, the type of (==) is
Eq a => a -> a -> Bool. The => is a type class constraint. We can
read this as: for any type a, as long as a is an instance of Eq,
(==) can take two values of a and return a Bool; it is a type
error to call the function (==) on some type which is not an instance
of Eq.
The (>>=) (bind) operator sequentially composes two actions, passing
any value produced by the first as an argument to the second. as >>= bs can be understood as:
do a <- as
bs a
dissects (>>=) :: m a -> (a -> m b) -> m b in an enlightening way. (>>=) takes two arguments. The first
one is a monadic value (or computation or mobit) that represents a
computation which results in a value (or several values, or no values)
of type a, and may have some sort of “effect”. The second argument is
a function of type a -> m b, i.e. it will choose the next computation
to run based on the result(s) of the first computation. Therein lies
the promised power of Monad to encapsulate computations which can
choose what to do next based on the results of previous computations.
offers several examples of mobits:
c1 :: Maybe ais a computation which might fail, but results in anaif it succeeds.c2 :: [a]is a computation which results in (multiple)as.c3 :: IO ais a computation which potentially has some I/O effects, and then produces ana.
Till now, I thought c2 :: [a] was a good old list!
Forums say that the Spring 2013 version of CIS 194 is the best one. I find the writings of Brent Yorgey , the Spring 2013 instructor, clearer.
The (>>) (“and then”) operator sequentially composes two actions,
discarding any value produced by the first. as >> bs can be
understood as:
do as
bs
Each statement in a do block is one of these:
- A single expression
e, which is then prepended to the rest withe >> ... - A monadic bind
p <- e, which is replaced bye >>= (\p -> ...) - A
letbindinglet p = e, which is translated tolet p = e in ...
… so main and main' are equivalent:
-- Side note: `readLn` throws an exception if the input is not a number.
-- Actual code should use `getLine`, `readMaybe`, and handle input that
-- is not a number. However, we're currently concerned with monads.
main :: IO ()
main = putStrLn "Please enter a number: " >>
readLn >> \n ->
let m = n + 1 in
putStrLn (show m)
main' :: IO ()
main' = do putStrLn "Please enter a number: "
n <- readLn
let m = n + 1
putStrLn (show m)
A Monad m also offers a return function of type a -> m a, which
injects a value into the monadic type.
There are still holes in my understanding of Monads. They relate to
Functors and Applicatives, and I don’t want to go into that rabbit
hole (yet). promises to help me develop an
intuition for this [scary] diagram.
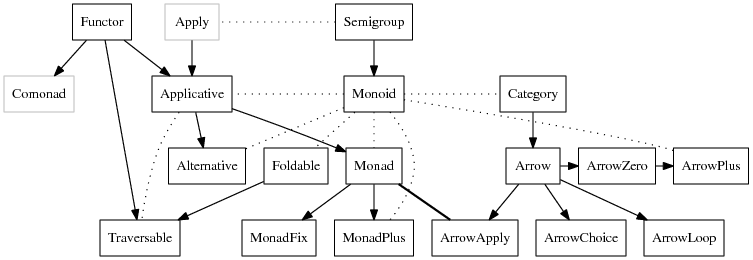
Graph of type classes and their relationships. Memorable
quote: What the heck is a monoid, and how is it different from a
monad? Credits:
target="_blank" rel="noopener"
>
https://wiki.haskell.org/Typeclassopedia
<i class="fas fa-fw fa-external-link-alt" aria-hidden="true"></i>
For now, my takeaway is: Monads encapsulate computations which can
choose what to do next based on the results of previous computations.
Functor
In hindsight, I should have started with exploring Functors, but here
I am exploring them after Monads.
text <- Text.lines <$> readFileUtf8 "data/day01.txt"
A simple intuition is that a Functor represents a “container” of some
sort, along with the ability to apply a function uniformly to every
element in the container. A more useful but more difficult to explain
intuition is that a Functor represents some sort of “computational
context”.
A Functor instance needs to implement fmap, whose type is fmap :: (a -> b) -> f a -> f b.. <$> is an infix synonym for fmap, which
allows for more readable code. Functor instances include [],
Maybe, Either, and IO.
My first reaction to the
accepted
answer
of, “What does <$>
mean in Haskell?” was “Wait, that’s a map; why need an fmap?” A
common argument is that it’d pretty a high barrier to spit out errors
about Functors to a newbie who is using map incorrectly.
The signature f a tells us that f is a sort of type function that
takes another type as a parameter, e.g. there are no values of type
Maybe, but we can have Maybe Integer. More precisely, the kind of
f must be * -> *. From the container PoV, fmap applies a function
to each element of a container, producing a new container of the same
structure. From the context PoV, fmap applies a function to a value in
a context, without altering its context.
fmap’s type with extra parentheses illustrates the concept of lifting.
fmap :: (a -> b) -> (f a -> f b) is more apparent that it transforms a
“normal” function (g :: a -> b) into one which operates over
containers/contexts fmap g :: f a -> f b.
References
- Advent of Code 2021. Johan Hidding. jhidding.github.io . Accessed Feb 20, 2022.
- Entangled: literate programming for the new millennium. Johan Hidding. entangled.github.io . github.com . Accessed Feb 20, 2022.
- rio: A standard library for Haskell. hackage.haskell.org . www.fpcomplete.com . github.com . Accessed Feb 20, 2022.
- mstksg/advent-of-code-2021: 🎅🌟❄️☃️🎄🎁. Justin Le. github.com . Accessed Feb 20, 2022.
- Welcome to Haddock’s documentation! — Haddock 1.0 documentation. haskell-haddock.readthedocs.io . Accessed Feb 20, 2022.
- Advent of Code 2021. Johan Hidding. jhidding.github.io . Accessed Feb 20, 2022.
- Control.Monad.IO.Class. hackage.haskell.org . Accessed Feb 21, 2022.
- 3: Recursion Patterns, Polymorphism, and the Prelude - School of Haskell. Brent Yorgey. www.schoolofhaskell.com . Jul 14, 2014. Accessed Feb 21, 2022.
- 6: Laziness - School of Haskell. Brent Yorgey. www.schoolofhaskell.com . Accessed Feb 21, 2022.
- CIS194 Fall 2016: IO and Monads. Joachim Breitner. www.cis.upenn.edu . Accessed Feb 21, 2022.
- Control.Monad. hackage.haskell.org . Accessed Feb 21, 2022.
- 5: Type Classes - School of Haskell. Brent Yorgey. www.schoolofhaskell.com . Accessed Feb 21, 2022.
- Associative property - Wikipedia. en.wikipedia.org . Accessed Feb 22, 2022.
- Identity element - Wikipedia. en.wikipedia.org . Accessed Feb 22, 2022.
- CIS194 Spring 2013: Monads. Brent Yorgey. www.cis.upenn.edu . Apr 8, 2013. Accessed Feb 22, 2022.
- Data.Functor. hackage.haskell.org . Accessed Feb 22, 2022.
- Typeclassopedia - HaskellWiki. Brent Yorgey. wiki.haskell.org . Accessed Feb 22, 2022.
- Advent of Code 2021: Day 2: Dive! jhidding.github.io . Accessed Feb 22, 2022.
- Text.Megaparsec. Mark Karpov. hackage.haskell.org . markkarpov.com . Accessed Feb 23, 2022.
- Haskell Extension for VS Code can't find GHC installed with nix-shell. Help! : haskell. www.reddit.com . Accessed Feb 25, 2022.
The folks at Stack maintain the Stackage package collection, a curated set of packages from Hackage which are tested for compatibility. This provides another proxy (in addition to Category:Libraries - HaskellWiki ) for determining which third-party library to build on when several claim to do the job.