Notable Benchmarks
Some notable benchmarks in language modeling:
- MMLU: 57 tasks spanning elementary math, US history, computer science, law, and more.
- EleutherAI Eval: Unified framework to test models via zero/few-shot settings on 200 tasks from various evals, including MMLU.
- HELM: Evaluates LLMs across domains; tasks include Q&A, information retrieval, summarization, text classification, etc.
- AlpacaEval: Measures how often a strong LLM (e.g., GPT-4) prefers the output of one model over a reference model.
Commonly Used Metrics
Bilingual Evaluation Understudy (BLEU)
\(\text{BLEU}\) counts the number of n-grams in the generated output that also show up in the reference, and then divides it by the total number of words in the output. To counter unigrams of common words from dominating, a brevity penalty is added to penalize excessively short sentences.
\(\text{BLEU}\) is predominantly used in machine translation.
Recall-Oriented Understudy for Gisting Evaluation (ROGUE)
\(\text{ROGUE}\) counts the number of words in the reference that also occur in the output. It has several variants:
- \(\text{ROGUE-N}\) also counts the number of matching n-grams between the output and the reference.
- \(\text{ROUGE-L}\) counts the longest common subsequence between the output and the reference.
- \(\text{ROUGE-S}\) measures the skip-bigram (pairs of words that maintain their relative order regardless of words sandwiched in between) between the output and the reference.
BERTScore
\(\text{BERTScore}\) uses contextualized embeddings and has 3 components:
- Recall: Average cosine similarity between each token in the reference and its closest match in the output.
- Precision: Average cosine similarity between each token in the output and its nearest match in the reference.
- F1: Harmonic mean of recall and precision.
Unlike \(\text{BLEU}\) and \(\text{ROGUE}\) which rely on exact matches, \(\text{BERTScore}\) can account for synonyms and paraphrasing. It has better correlation for image captioning and machine translation.
MoverScore
\(\text{MoverScore}\) is like \(\text{BERTScore}\), but allows for many-to-one matching (soft-alignment) instead of one-to-one matching (hard alignment). \(\text{MoverScore}\) measures the distance that words would have to move to convert one sequence to another.
Pitfalls to Using Conventional Benchmarks and Metrics
Poor correlation between these metrics and human judgments. \(\text{BLEU}\) and \(\text{ROUGE}\) have negative correlations w/ how humans evaluate fluency, and low correlation with tasks that require creativity and diversity.
Poor adaptability. Exact match metrics like \(\text{BLEU}\) and \(\text{ROGUE}\) are a poor fit for abstract summarization and dialog where an output can have zero n-gram overlap with the reference but yet be a good response.
Poor reproducibility. Attributed to variations in human judgement collection, metric parameter settings, incorrect eval implementations, different prompts of the same example across eval providers.
Using a Strong LLM as a Reference-Free Metric
\(\text{G-EVAL}\) is a framework that applies LLMs to evaluate LLM outputs. Give the LLM a Task Introduction and Evaluation Criteria, and then ask it to generate a Chain-of-Thought (CoT) of detailed Evaluation Steps. Concatenate the prompt, CoT, input and output, and ask the LLM to output a score. Use the probability-weighted summation of the output scores as the final score.
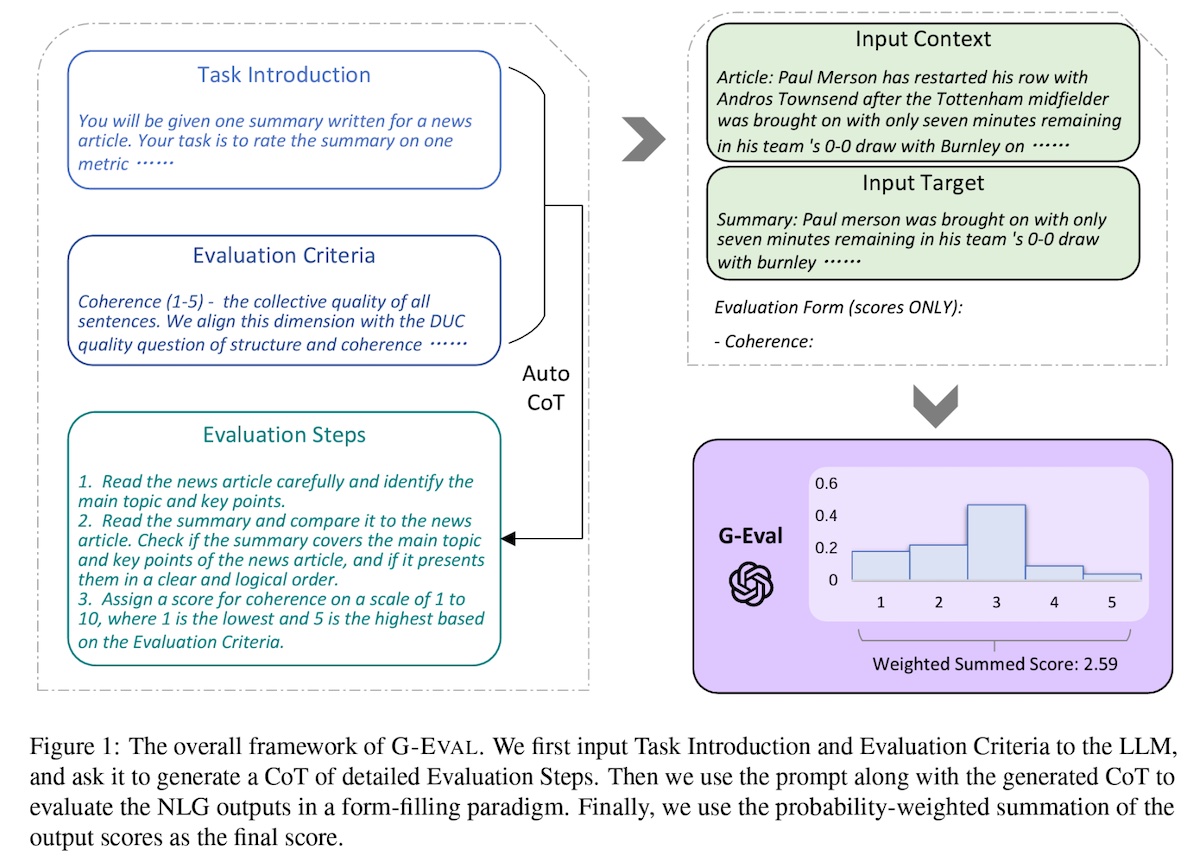
Overall framework of G-EVAL.
GPT-4 as an evaluator had a high Spearman correlation with human judgements (\(0.514\)), outperforming all previous methods. LLM-based automated evals could be a cost-effective and reasonable alternative to human evals.
How to Apply Evals
Eval Driven Development. Collect a set of task-specific evals (i.e., prompt, context, expected outputs). These evals then guide prompt engineering, model selection, fine-tuning, and so on.
Compared to human judgements, LLM judgements tend to be less noisy (more systematic bias) but more biased. Mitigate these biases:
- Position bias: LLMs tend to favor the response in the first position. Evaluate the same pair of responses twice while swapping their order. Only mark wins when the same response is preferred in both orders.
- Verbosity bias: LLMs tend to favor wordier responses. Ensure that comparison responses are similar in length.
- Self-enhancement bias: Don’t use the same LLM for evaluation tasks.
References
- Patterns for Building LLM-based Systems & Products. eugeneyan.com . Accessed Apr 6, 2025.