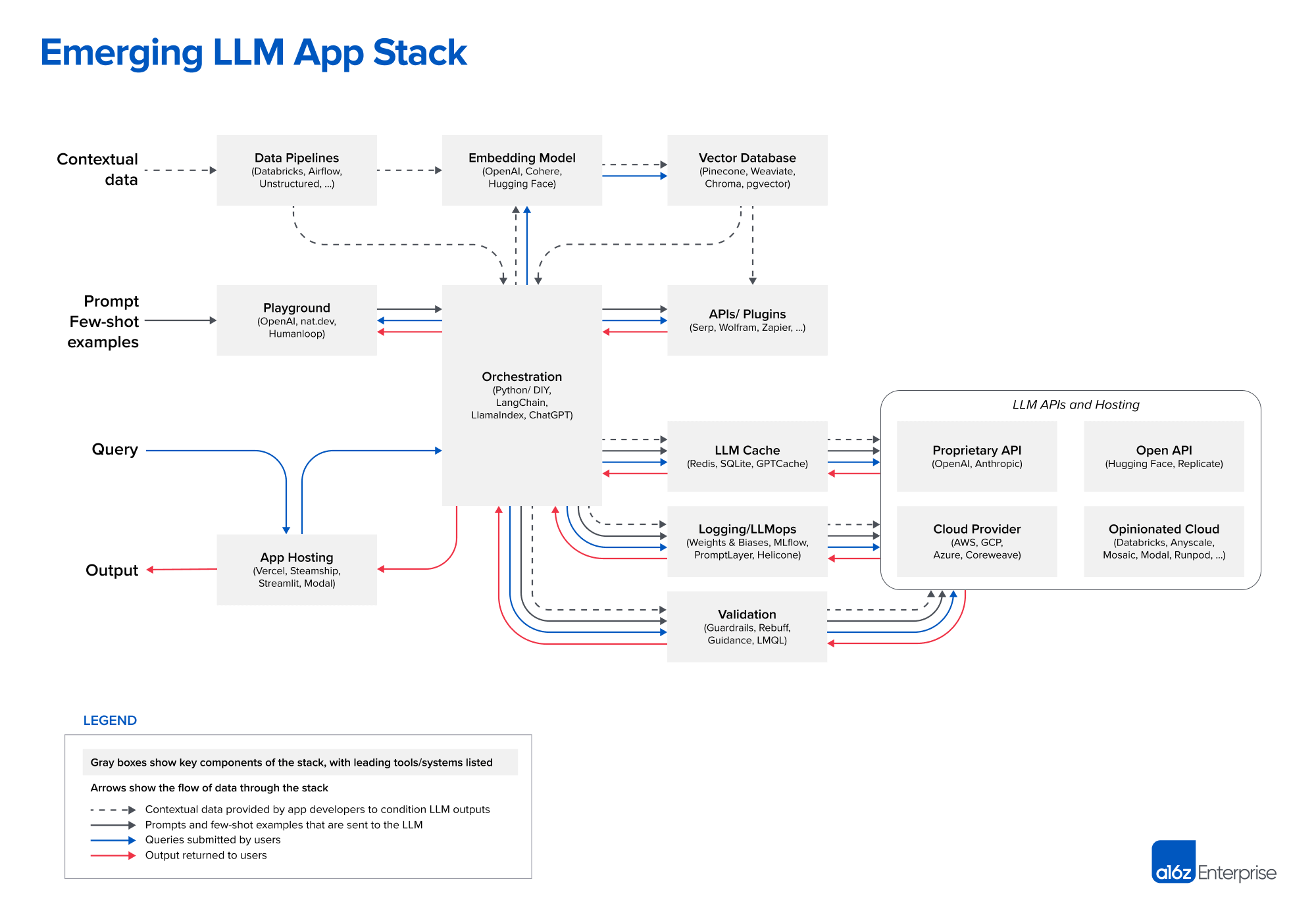
Emerging LLM App Stack. Credits: a16z.com
Design Pattern: In-Context Learning
Betting on the LLM’s context window increasing doesn’t pay off. As the input approaches the limits of the context window, inference time and accuracy degrade.
Instead, the typical workflow of in-context learning is:
- Data Pre-processing/Embedding. Compute and store embeddings of the private data in a vector database.
- Prompt Construction/Retrieval. On user input, compile a prompt from a hard-coded template with few-shot examples, information retrieved from external APIs, and a set of relevant documents retrieved from the vector database.
- Prompt Execution/Inference. Submit the compiled prompt to a pre-trained LLM for inference. Can add logging, caching, and validation at this stage.
The in-context learning reduces the AI problem into a data engineering problem.
Deterministic Control Flows vs. Prompting
I’m apprehensive of cases where I leaned more on prompting instead of writing deterministic code. It seems to me that the orchestration and context management is just as, if not more, important than the prompting piece.
Resorting to MANDATORY or DO NOT SKIP is a code-smell for reaching the ceiling of prompting. Code exposes predictable behavior, enabling local reasoning; prompt chains lack this property as they are non-deterministic, weakly specified, and difficult to verify.
Choose deterministic scaffolding/orchestration: explicit state transitions, and validation checkpoints that treat the LLM as a component, not the system. Build in aggressive error detection lest you’re on the fast lane to the wrong conclusion.
“Look in this directory at the requirements files. For each requirement file, create a todo list item to determine id the application meets the requirements outlined in that file…” The LLM was not consistent and would break down after ~30 files. What worked was a basic harness that triggered the model for each test case, store the results in an array, and then write the results in a file.
It may be that the LLM pushers encourage prompt-only workflows not because we don’t pay them for the scaffolding, but because the scaffolding runs counter of “replace entire people in entire workflows” sales pitch.
Breaking down tasks into smaller and easier to consume chunks also allows you to get away with a much less capable LLM to get comparable results.
Use LLMs to write scripts, then call the scripts from your looping harness. Call out to LLMs only for those parts that are hard to automate, with some deterministic validation at the end.
When the LLM asks if it can run a script, ask yourself whether it should write a tool that you can read once and then auto-approve for all future executions.
Think about agents declaratively rather than designing rube-goldberg harnesses. Give them a goal, tools, constraints, and a validation mechanism for the agent to self-correct. Don’t constrain what the agent does; you’re paying agent reasoning not an expensive data transformation pipeline.
References
- Emerging Architectures for LLM Applications | Andreessen Horowitz. a16z.com . Accessed Apr 6, 2025.
- Agents need control flow, not more prompts | brian's thoughts. bsuh.bearblog.dev . Accessed May 7, 2026.
- Agents need control flow, not more prompts | Hacker News. news.ycombinator.com . Accessed May 7, 2026.
I’ve arrived to this on a smaller scale. Sure, I can use the LLM to query a Kusto database. But there are queries that I tend to come back to, and for those, saving the actual KQL and running it w/o involving the LLM saves me time while always getting me the results that I want.